
Innovations in deep learning (DL), especially the rapid growth of large language models (LLMs), have taken the industry by storm. DL models have grown from millions to billions of parameters and are demonstrating exciting new capabilities. They are fueling new applications such as generative AI or advanced research in healthcare and life sciences. AWS has been innovating across chips, servers, data center connectivity, and software to accelerate such DL workloads at scale.
At AWS re:Invent 2022, we announced the preview of Amazon EC2 Inf2 instances powered by AWS Inferentia2, the latest AWS-designed ML chip. Inf2 instances are designed to run high-performance DL inference applications at scale globally. They are the most cost-effective and energy-efficient option on Amazon EC2 for deploying the latest innovations in generative AI, such as GPT-J or Open Pre-trained Transformer (OPT) language models.
Today, I’m excited to announce that Amazon EC2 Inf2 instances are now generally available!
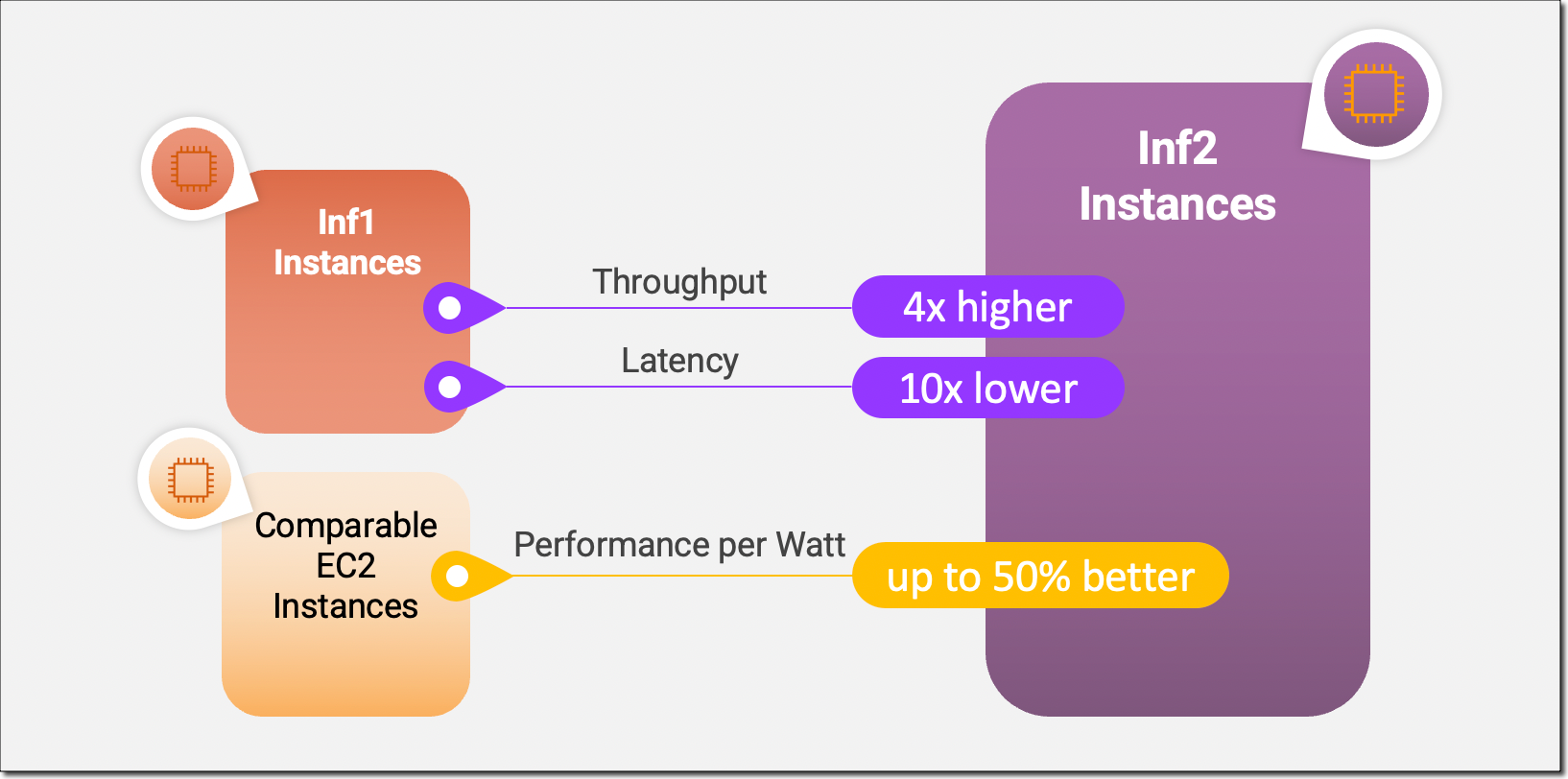
Inf2 instances are the first inference-optimized instances in Amazon EC2 to support scale-out distributed inference with ultra-high-speed connectivity between accelerators. You can now efficiently deploy models with hundreds of billions of parameters across multiple accelerators on Inf2 instances. Compared to Amazon EC2 Inf1 instances, Inf2 instances deliver up to 4x higher throughput and up to 10x lower latency. Here’s an infographic that highlights the key performance improvements that we have made available with the new Inf2 instances:
{kind=link}
New Inf2 Instance Highlights
Inf2 instances are available today in four sizes and are powered by up to 12 AWS Inferentia2 chips with 192 vCPUs. They offer a combined compute power of 2.3 petaFLOPS at BF16 or FP16 data types and feature an ultra-high-speed NeuronLink interconnect between chips. NeuronLink scales large models across multiple Inferentia2 chips, avoids communication bottlenecks, and enables higher-performance inference.
Inf2 instances offer up to 384 GB of shared accelerator memory, with 32 GB high-bandwidth memory (HBM) in every Inferentia2 chip and 9.8 TB/s of total memory bandwidth. This type of bandwidth is particularly important to support inference for large language models that are memory bound.
Since the underlying AWS Inferentia2 chips are purpose-built for DL workloads, Inf2 instances offer up to 50 percent better performance per watt than other comparable Amazon EC2 instances. I’ll cover the AWS Inferentia2 silicon innovations in more detail later in this blog post.
The following table lists the sizes and specs of Inf2 instances in detail.
Instance Name
vCPUs
AWS Inferentia2 Chips
Accelerator Memory
NeuronLink
Instance Memory
Instance Networking
inf2.xlarge
4
1
32 GB
N/A
16 GB
Up to 15 Gbps
inf2.8xlarge
32
1
32 GB
N/A
128 GB
Up to 25 Gbps
inf2.24xlarge
96
6
192 GB
Yes
384 GB
50 Gbps
inf2.48xlarge
192
12
384 GB
Yes
768 GB
100 Gbps
AWS Inferentia2 Innovation
Similar to AWS Trainium chips, each AWS Inferentia2 chip has two improved NeuronCore-v2 engines, HBM stacks, and dedicated collective compute engines to parallelize computation and communication operations when performing multi-accelerator inference.
Each NeuronCore-v2 has dedicated scalar, vector, and tensor engines that are purpose-built for DL algorithms. The tensor engine is optimized for matrix operations. The scalar engine is optimized for element-wise operations like ReLU (rectified linear unit) functions. The vector engine is optimized for non-element-wise vector operations, including batch normalization or pooling.
Here is a short summary of additional AWS Inferentia2 chip and server hardware innovations:
Data Types – AWS Inferentia2 supports a wide range of data types, including FP32, TF32, BF16, FP16, and UINT8, so you can choose the most suitable data type for your workloads. It also supports the new configurable FP8 (cFP8) data type, which is especially relevant for large models because it reduces the memory footprint and I/O requirements of the model. The following image compares the supported data types.
Dynamic Execution, Dynamic Input Shapes – AWS Inferentia2 has embedded general-purpose digital signal processors (DSPs) that enable dynamic execution, so control flow operators don’t need to be unrolled or executed on the host. AWS Inferentia2 also supports dynamic input shapes that are key for models with unknown input tensor sizes, such as models processing text.
Custom Operators – AWS Inferentia2 supports custom operators written in C++. Neuron Custom C++ Operators enable you to write C++ custom operators that natively run on NeuronCores. You can use standard PyTorch custom operator programming interfaces to migrate CPU custom operators to Neuron and implement new experimental operators, all without any intimate knowledge of the NeuronCore hardware.
NeuronLink v2 – Inf2 instances are the first inference-optimized instance on Amazon EC2 to support distributed inference with direct ultra-high-speed connectivity—NeuronLink v2—between chips. NeuronLink v2 uses collective communications (CC) operators such as all-reduce to run high-performance inference pipelines across all chips.
{kind=link}
The following Inf2 distributed inference benchmarks show throughput and cost improvements for OPT-30B and OPT-66B models over comparable inference-optimized Amazon EC2 instances.
{kind=link}
Now, let me show you how to get started with Amazon EC2 Inf2 instances.
Get Started with Inf2 Instances
The AWS Neuron SDK integrates AWS Inferentia2 into popular machine learning (ML) frameworks like PyTorch. The Neuron SDK includes a compiler, runtime, and profiling tools and is constantly being updated with new features and performance optimizations.
In this example, I will compile and deploy a pre-trained BERT model from Hugging Face on an EC2 Inf2 instance using the available PyTorch Neuron packages. PyTorch Neuron is based on the PyTorch XLA software package and enables the conversion of PyTorch operations to AWS Inferentia2 instructions.
SSH into your Inf2 instance and activate a Python virtual environment that includes the PyTorch Neuron packages. If you’re using a Neuron-provided AMI, you can activate the preinstalled environment by running the following command:
source aws_neuron_venv_pytorch_p37/bin/activate
Now, with only a few changes to your code, you can compile your PyTorch model into an AWS Neuron-optimized TorchScript. Let’s start with importing torch, the PyTorch Neuron package torch_neuronx, and the Hugging Face transformers library.
import torch
import torch_neuronx from transformers import AutoTokenizer, AutoModelForSequenceClassification
import transformers
…
Next, let’s build the tokenizer and model.
name = “bert-base-cased-finetuned-mrpc”
tokenizer = AutoTokenizer.from_pretrained(name)
model = AutoModelForSequenceClassification.from_pretrained(name, torchscript=True)
We can test the model with example inputs. The model expects two sentences as input, and its output is whether or not those sentences are a paraphrase of each other.
def encode(tokenizer, *inputs, max_length=128, batch_size=1):
tokens = tokenizer.encode_plus(
*inputs,
max_length=max_length,
padding=’max_length’,
truncation=True,
return_tensors=”pt”
)
return (
torch.repeat_interleave(tokens[‘input_ids’], batch_size, 0),
torch.repeat_interleave(tokens[‘attention_mask’], batch_size, 0),
torch.repeat_interleave(tokens[’token_type_ids’], batch_size, 0),
)
# Example inputs
sequence_0 = “The company Hugging Face is based in New York City”
sequence_1 = “Apples are especially bad for your health”
sequence_2 = “Hugging Face’s headquarters are situated in Manhattan”
paraphrase = encode(tokenizer, sequence_0, sequence_2)
not_paraphrase = encode(tokenizer, sequence_0, sequence_1)
# Run the original PyTorch model on examples
paraphrase_reference_logits = model(*paraphrase)[0]
not_paraphrase_reference_logits = model(*not_paraphrase)[0]
print(‘Paraphrase Reference Logits: ‘, paraphrase_reference_logits.detach().numpy())
print(‘Not-Paraphrase Reference Logits:’, not_paraphrase_reference_logits.detach().numpy())
The output should look similar to this:
Paraphrase Reference Logits: [[-0.34945598 1.9003887 ]]
Not-Paraphrase Reference Logits: [[ 0.5386365 -2.2197142]]
Now, the torch_neuronx.trace() method sends operations to the Neuron Compiler (neuron-cc) for compilation and embeds the compiled artifacts in a TorchScript graph. The method expects the model and a tuple of example inputs as arguments.
neuron_model = torch_neuronx.trace(model, paraphrase)
Let’s test the Neuron-compiled model with our example inputs:
paraphrase_neuron_logits = neuron_model(*paraphrase)[0]
not_paraphrase_neuron_logits = neuron_model(*not_paraphrase)[0]
print(‘Paraphrase Neuron Logits: ‘, paraphrase_neuron_logits.detach().numpy())
print(‘Not-Paraphrase Neuron Logits: ‘, not_paraphrase_neuron_logits.detach().numpy())
The output should look similar to this:
Paraphrase Neuron Logits: [[-0.34915772 1.8981738 ]]
Not-Paraphrase Neuron Logits: [[ 0.5374032 -2.2180378]]
That’s it. With just a few lines of code changes, we compiled and ran a PyTorch model on an Amazon EC2 Inf2 instance. To learn more about which DL model architectures are a good fit for AWS Inferentia2 and the current model support matrix, visit the AWS Neuron Documentation.
Available Now
You can launch Inf2 instances today in the AWS US East (Ohio) and US East (N. Virginia) Regions as On-Demand, Reserved, and Spot Instances or as part of a Savings Plan. As usual with Amazon EC2, you pay only for what you use. For more information, see Amazon EC2 pricing.
Inf2 instances can be deployed using AWS Deep Learning AMIs, and container images are available via managed services such as Amazon SageMaker, Amazon Elastic Kubernetes Service (Amazon EKS), Amazon Elastic Container Service (Amazon ECS), and AWS ParallelCluster.
To learn more, visit our Amazon EC2 Inf2 instances page, and please send feedback to AWS re:Post for EC2 or through your usual AWS Support contacts.
— Antje